


COO @ Quorivex Systems
We wanted to automate a few workflows but weren't sure where to start. Lampros helped us cut through the noise and get something useful into production quickly.

CTO @ Teralynx Systems
They picked up our processes surprisingly fast and built around how we already worked instead of forcing us into a new system.

Financial Technology Company
We saw value pretty quickly. A lot of repetitive work that used to take hours every week simply stopped being a problem. Our team could focus on higher-value work instead.
Contact Us
Ready to Ship AI Systems to
Let's align architecture, execution, and delivery from day one.
Published On Aug 28, 2025
Updated On Aug 28, 2025

On-chain data is often described as the ultimate source of truth in blockchain. Every block is permanent, every transaction is transparent, and every state change is recorded.
But when you look across the system and try to build analytics, risk systems, or governance dashboards on top of it, fault lines in trust appear.
The challenge isn’t that data doesn’t exist; it’s that at scale, it becomes fragmented, inconsistent, and sometimes misleading.
What appears to be clarity at the protocol level can quickly turn into noise when billions of dollars depend on the numbers being accurate.
This blog explores that tension: why on-chain data, despite its transparency, is difficult to trust at scale.
We’ll define what actually counts as on-chain data, examine the practical reasons trust breaks down, and outline the real-world costs of getting it wrong, as well as frameworks and tools that help rebuild reliability.
Let’s get started.
On-chain data includes blocks, transactions, state, logs, rollup proofs, and bridge records. It’s often treated as a single source of truth, but in 2025, it’s fragmented across L1s, L2s, and DA layers.
Billions move daily through DeFi and DAOs. When analytics depend on partial or inconsistent data, trust breaks, leading to misreported TVL, treasury leaks, or governance disputes.
Six recurring gaps drive drift:
In 2025, hacks topped $1.7B in four months, nearly half of DeFi projects report unverifiable TVL, and bridges move $24B monthly while remaining the leading vector for systemic loss.
To build reliable on-chain analytics, teams need trust-first pipelines with layered controls: multiple RPCs for consistency, metric contracts for clarity, lineage proofs for verifiability, blob capture for retention, and continuous verification to keep drift in check.
On-chain data doesn’t fail at the chain level; it fails in how we capture, store, and interpret it. In a modular, multi-chain world, only trust-first analytics will stand up to scrutiny.
Let’s deep dive into what on-chain data is, where its limitations lie, and how layered controls can make it provable, not just available.
On-chain data refers to all information that is permanently recorded and verifiable within a blockchain network.
This includes the blocks themselves, the transactions they contain, and the resulting changes in state. Unlike off-chain data, which relies on third-party reporting or external oracles, on-chain data is embedded in the consensus process of the chain.
But in 2025, that definition needs more precision. The blockchain stack has expanded far beyond base-layer transactions on Ethereum or Bitcoin. Today, “on-chain data” spans:
Each of these carries different guarantees. For example, Ethereum’s execution layer data is final once the chain reaches consensus, but rollup transaction data may only be trustworthy once its proof window has closed.
Similarly, Ethereum “blob” data introduced with proto-danksharding (EIP-4844) is only guaranteed to be available for a limited retention period, which introduces new risks for teams building historical analytics pipelines.
This makes even the basic act of defining “on-chain data” a non-trivial decision. What one team considers canonical, e.g., ERC-20 transfer events, may in practice be incomplete or even misleading, while another team might define “on-chain data” more strictly as raw state transitions.
In short, on-chain data is not a single dataset; it’s a layered set of records whose trustworthiness depends on where you draw the boundary and how you access it.
At scale, those layers overlap and conflict across chains, rollups, and DA systems, turning what looks like a single source of truth into inconsistent and incomplete signals.
This is where trust begins to break.
On-chain data looks absolute in principle: every block is immutable, every transaction recorded, every state change transparent.
But scale changes the picture. As ecosystems stretch across rollups, bridges, and modular DA layers, the guarantees that look solid at the block level begin to weaken.
Trust breaks not because the blockchain itself stops working, but because the way data is stored, accessed, and interpreted introduces gaps.
Here are the six most common ways those gaps surface:
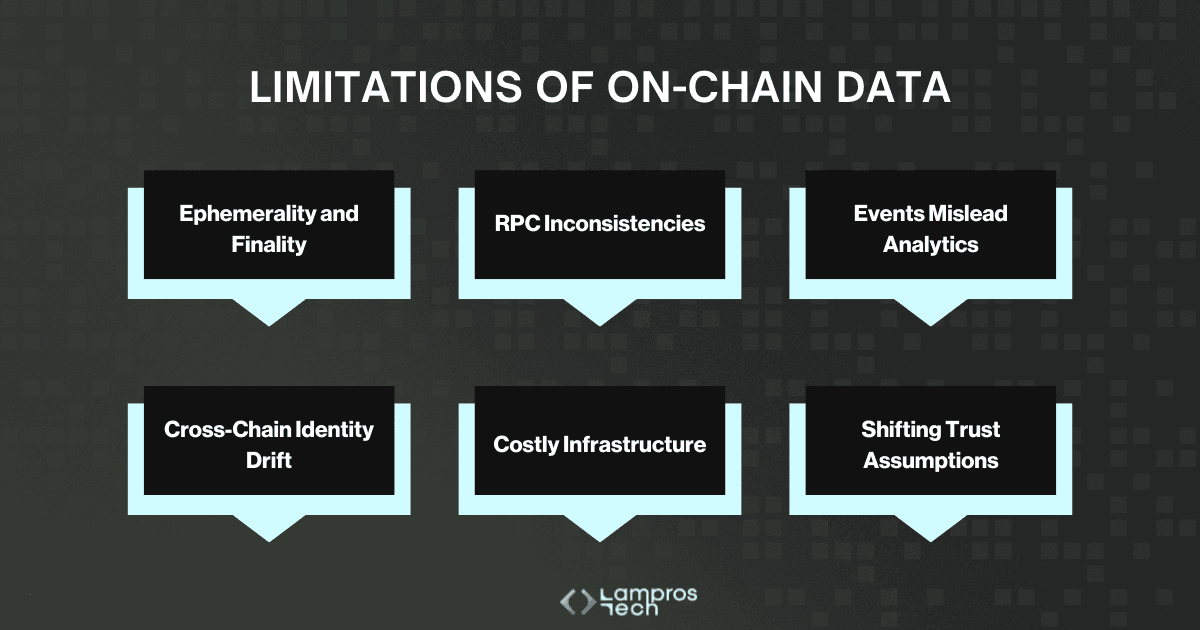
Blockchains are often treated as permanent ledgers, but not all data is kept forever.
Ethereum’s blobs (introduced in EIP-4844) are pruned after roughly 18 days. Celestia retains about 30 days of light client access, while EigenDA ties retention to economic incentives.
For anyone building analytics, this means history can literally vanish unless you capture it yourself. Finality adds another layer: optimistic rollups can take up to two weeks to finalise, while ZK rollups are instant only if provers are available.
Why it matters: Teams basing audits or governance on “available” data risk losing historical completeness overnight. Without archiving, you may not even be able to re-create your own metrics.
Most developers and analysts interact with blockchains through RPC endpoints, not raw nodes. But RPC providers don’t all return the same answers.
Some prune old state aggressively, others sync more slowly, and each has its own policy for handling reorgs. Even a simple “eth_getLogs” call may produce different results depending on where you query.
On top of that, mempool data is increasingly redacted to reduce MEV exposure, meaning what you see is a filtered version of reality.
Why it matters: Two teams can query the same block and get different results. Metrics built on one provider may not reproduce elsewhere, undermining credibility in governance or reporting.
It’s convenient to build dashboards by indexing contract events like “Transfer”. The problem is, events aren’t consensus-critical.
A token can rebase balances without emitting an event, or charge fees on transfers that never appear in logs.
Attackers have even spoofed fake events to inflate token volumes. And as ERC-4337 adoption grows, account abstraction introduces new event structures that older pipelines weren’t built to capture.
Why it matters: If your pipeline trusts events as “truth,” you will miscount balances, volumes, and liquidity. In some cases, attackers exploit these blind spots to drain incentives or manipulate market perception.
Assets no longer live in one place. A single token like USDC now exists as a native asset, as a bridged version, and as wrapped derivatives across Ethereum, Arbitrum, Optimism, and Base.
Unless those forms are reconciled, analytics will double-count liquidity or overstate supply. The problem intensifies on Orbit chains and appchains, where custom bridges create even more divergence.
Without strict mapping rules, the same “asset” quickly becomes multiple, conflicting records.
Why it matters: Misstating supply or liquidity leads directly to inflated TVL, incorrect risk assessments, and governance disputes over “phantom” assets.
The cost of keeping perfect history is high. Running an archive node for full historical access can cost thousands per month, so most teams rely on third-party RPCs or indexers.
That means inheriting their pruning decisions, reorg handling, and outages. Even subtleties like block timestamp manipulation, where validators nudge block times, can distort time-series analytics.
Backfills often happen in chunks, and interruptions leave silent gaps that corrupt datasets without anyone noticing until incentives or governance decisions go wrong.
Why it matters: Silent data gaps erode trust. By the time a treasury overpays incentives or a DAO disputes voter balances, the underlying hole is nearly impossible to patch retroactively.
Finally, what “on-chain” means has changed. Ethereum’s execution layer offers one set of guarantees, while rollups introduce others, and DA layers like Celestia, Avail, and EigenDA add their own.
Each defines finality, retention, and verifiability differently. A dataset pulled from one layer can’t be assumed to carry the same guarantees as another.
Why it matters: Without recognising these differing assumptions, teams build analytics that look correct but rest on mismatched definitions of “truth.”
This framework doesn’t remove complexity, but it replaces assumptions with proof.
The closer you get to production-grade analytics, the clearer it becomes: on-chain data is not inherently trustworthy; it has to be made trustworthy.
And when it isn’t, the cost appears quickly, in financial losses, misreported metrics, and governance disputes. Let’s examine what that failure has actually entailed.
When teams build analytics, dashboards, governance, or risk systems atop on-chain data, even subtle inconsistencies can create cascading failures.
Below, the stakes are illustrated with vivid 2025 examples that highlight not just that failures occur, but how they multiply in impact as scale grows.
Why it matters: As you scale analytics across L1s, L2s, and bridges, reliance on incomplete or untimely data can mask early exploit patterns. By the time anomalies surface, it’s too late.
Why it matters: Decisions based on inflated or unverifiable TVL, whether for governance, investments, or incentive design, are built on shifting sands. Without rigorous, on-chain only baselining, trust fades.
Why it matters: With immense volumes flowing through rollups and modular DA layers, any trust gap, whether in rollup finality, blob retention, or cross-chain reconciliation, can amplify into large-scale financial, reputational, or governance damage.
Why it matters: Bridges distribute trust assumptions across disparate chains. Without robust verification of cross-chain state, analytics misstate liquidity, transfers, or TVL, creating misaligned user experiences, financial misreporting, and governance blind spots.
These aren’t abstract risks. They’re escalating threats in 2025 as ecosystems multiply, chains diversify, and data complexity explodes.
If analytics pipelines trust data that’s partial, delayed, or reinvented, the consequences are immediate that are financial loss, governance breakdown, and erosion of credibility.
Next, we’ll see how to build a blueprint for Trust Architecture for On-Chain Data, a structure of controls, observability, and lineage that restores confidence and scales with complexity.
On-chain data is often assumed to be “the truth you can build on.” But as we’ve seen, the reality is more complex. Data gets pruned, events can be spoofed, and bridges create multiple versions of the same asset.
If a protocol team, DAO, or analyst treats raw data as perfect, the downstream metrics like TVL, liquidity, or supply quickly drift from reality.
That’s why serious teams now design trust architecture: a set of controls and processes that turn messy blockchain records into datasets that can actually be relied on.
Think of it as moving from “data is available” to “data is verifiable, reproducible, and auditable.”
With this framing in mind, the real question becomes: how do you architect your systems so that the numbers you publish remain consistent, defensible, and trusted even under scale?
Trust doesn’t end at producing a number; you need to be able to show your work.
Ethereum’s blobs introduced in EIP-4844 are only retained for about 18 days, Celestia for ~30 days on light clients, and EigenDA according to its economic settings.
If you don’t capture and store this data locally, history literally disappears.
The solution is to treat availability as part of your trust model:
Even with controls in place, pipelines drift unless they’re constantly tested.
This architecture doesn’t make data perfect; it makes it provable.
Every number can be traced back to its origin, verified against multiple sources, and reproduced later. That is the standard protocols, treasuries, and DAOs will increasingly need as billions of dollars flow through modular chains and bridges.
To reach that standard, teams now rely on a new wave of infrastructure. In 2025, several tools have emerged that make trust-first data pipelines practical in production.
Designing trust architecture in theory is one thing, and operating it at scale is another.
Fortunately, the last two years have seen a new generation of data infrastructure tools emerge, purpose-built for modular, multi-chain ecosystems.
They fall into five main patterns: deterministic indexing and ingestion, data availability, provenance and attestation layers, observability frameworks, and privacy-safe access.
A trust-first pipeline in 2025 typically looks like this:
This pattern doesn’t eliminate complexity, but it transforms raw blockchain data into something communities can actually rely on.
The next step is applying these patterns to real metrics, which balances liquidity, rollup health, and governance, to see how a trust-first approach works in practice.
It’s one thing to design architecture; it’s another to apply it to the metrics everyone uses daily.
Before doing that, it’s important to weigh the build vs buy trade-offs in Web3 analytics, as your approach to infrastructure directly impacts reliability and scale.
Below are examples of how teams in 2025 can apply trust-first principles across balances, DEX volumes, rollup health, and governance analytics.
Each of these controls moves pipelines away from fragile event-only assumptions and towards state-verified, reproducible, and auditable metrics.
By treating metrics like products with schemas, invariants, and continuous verification, teams can prevent errors that would otherwise drain treasuries, mislead governance, or distort markets.
To make this actionable, here’s a practical checklist of the controls every team can apply when building trust-first pipelines.
Building trust into on-chain data pipelines isn’t about adding one new tool or patch. It’s about layering controls so that every number is defensible.
Here’s a practical checklist teams can adopt:
By applying this checklist, teams shift from dashboards that merely look complete to infrastructures that can be proven complete.
In a multi-chain, modular world, that is the only path to data that communities, investors, and regulators will actually trust.
On-chain data is often described as transparent and final.
But at scale, transparency without verification creates as many problems as it solves. Data fragments across rollups, bridges, and DA layers. Blobs expire, RPCs disagree, and token mechanics break naïve assumptions.
The result is dashboards that look precise but conceal silent errors; errors that drain treasuries, distort governance, or hide security risks until it’s too late.
The shift that protocols, DAOs, and investors need is from “data is available” to “data is provable.” That means designing pipelines with explicit acquisition rules, semantic contracts, lineage tracking, availability safeguards, and continuous verification.
In 2025’s modular, multi-chain world, these aren’t nice-to-haves; they’re survival requirements.
Teams that treat on-chain data as infrastructure, not an afterthought, will be the ones whose analytics still stand up to scrutiny years later. And for ecosystems built on trust, that difference is existential.
At Lampros Tech, we help blockchain teams build trust-first analytics.
Whether you need real-time dashboards, governance-grade reporting, or cross-chain risk monitoring, our Web3 Data Analytics services turn raw blockchain data into reliable, verifiable insights.
We design pipelines with the accuracy, transparency, and resilience that today’s protocols demand.

On-chain data includes blocks, transactions, receipts, contract state, rollup proofs, data availability blobs, and cross-chain messages. Each carries different guarantees of permanence and verifiability.
As ecosystems expand across rollups, bridges, and DA layers, data gets pruned, RPCs disagree, events can be spoofed, and assets drift across chains. These create inconsistencies that undermine trust.
Teams risk misreported TVL, inflated liquidity, treasury losses, governance disputes, and undetected exploits when analytics pipelines assume raw on-chain data is always accurate.
By designing trust architecture: using multiple RPC sources, respecting finality, handling reorgs, encoding token behaviors, reconciling cross-chain assets, capturing blob data, and verifying metrics continuously.
Substreams, Subsquid, and Goldsky for deterministic ingestion; Celestia, EigenDA, and Avail for DA storage; EAS for attestations; IPFS/Arweave for content-addressing; and invariant checks for continuous verification.


