


COO @ Quorivex Systems
We wanted to automate a few workflows but weren't sure where to start. Lampros helped us cut through the noise and get something useful into production quickly.

CTO @ Teralynx Systems
They picked up our processes surprisingly fast and built around how we already worked instead of forcing us into a new system.

Financial Technology Company
We saw value pretty quickly. A lot of repetitive work that used to take hours every week simply stopped being a problem. Our team could focus on higher-value work instead.
Contact Us
Ready to Ship AI Systems to
Let's align architecture, execution, and delivery from day one.
Published On Apr 10, 2026
Updated On Apr 10, 2026

Choosing the right AI agent framework in 2026 is one of the most consequential architectural decisions an engineering team can make.
The AI agent orchestration layer, not the model, now determines whether your production system holds up under real-world conditions.
Two years ago, picking an AI framework was a straightforward decision.
You chose PyTorch or TensorFlow, trained your model, wrapped it in an API, and shipped. The framework was a training tool. The model was the product.
That world is gone.
In 2026, the model has become a commodity. GPT-4 class intelligence is available from a dozen providers.
What differentiates production AI systems now is all about the AI stack and orchestration layer, the framework that determines how an agent plans, executes, recovers from errors, maintains state, and hands off tasks to other agents.
The framework is the product.
But most teams do not realise this until something breaks in production.
And when it does, it rarely looks like a model problem.
Most framework comparisons still evaluate tools as model wrappers: which one has the best OpenAI integration, which one is easiest to get running, which one has the most stars on GitHub.
That framing was useful in 2023. It is dangerously misleading in 2026.
In production agentic systems, the model is rarely the failure point. The orchestration layer around it almost always is.
Production agent failures break down into four recurring categories.
Key insight: These four failure modes are not model problems. They are infrastructure problems. Switching from GPT-4o to Claude 3.5 does not solve them. Switching to LangGraph or redesigning your state management usually does.
This is the lens through which we evaluate every framework in this guide: not "how fast can I get a demo running," but "how does this behave when something goes wrong at step seven of a twelve-step workflow."
If failures in agent systems are driven by orchestration, not models, then the real question is:
which frameworks actually solve these failure modes in production?
That is what we evaluate next.
Best for: Rapid prototyping and tool-heavy integrations
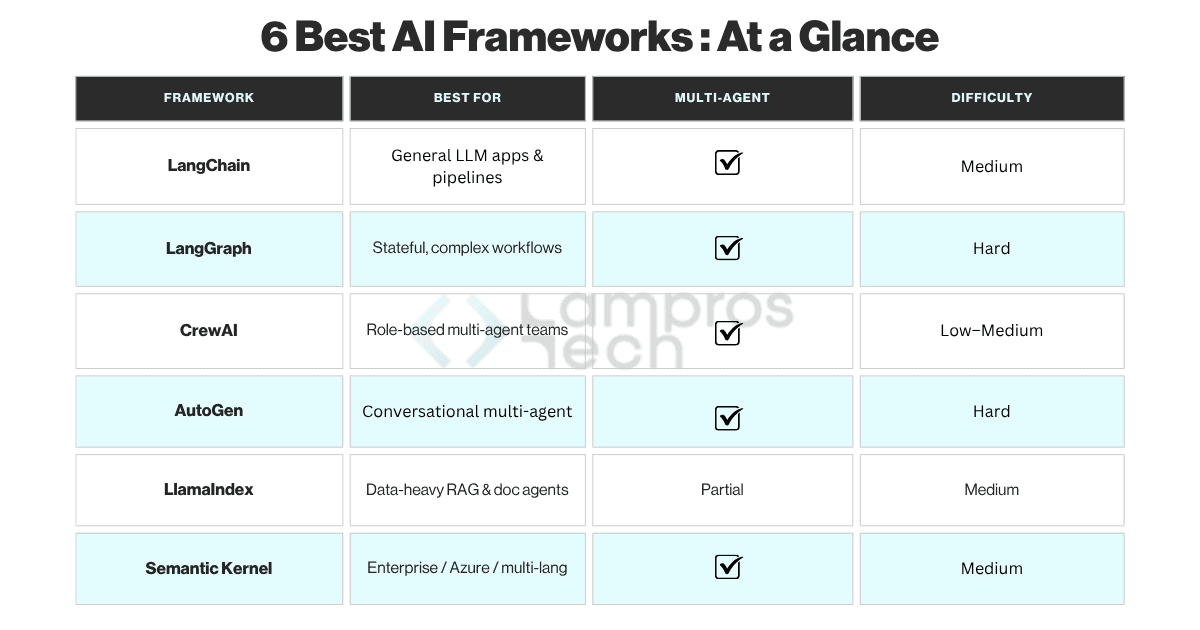
LangChain remains the default entry point into agent development and for good reason.
It has the broadest integration coverage of any framework, with connectors for OpenAI, Anthropic, Google, Cohere, and dozens of vector databases, tool providers, and memory backends.
For assembling a working proof of concept in hours rather than days, nothing matches it.
The critical thing to understand about LangChain is what it is not: it is not an execution framework.
It has no native concept of persistent state, no retry mechanism, and no explicit control over the transition between steps.
It is an integration and templating layer, extraordinarily useful in that role, and frequently misused outside it.
Use it when:
Avoid relying on it for:
Best for: Deterministic, stateful, production-grade agents
LangGraph was built to solve the exact four failure modes described above.
It introduces a graph-based execution model where each node represents a task, tool call, or model invocation, and edges define the explicit transitions between them.
State is not inferred or hoped-for, it is declared, passed explicitly between nodes, and persisted.
From a backend engineering perspective, LangGraph is the first AI orchestration framework that thinks like infrastructure.
It gives you retry policies at the node level, conditional branching, cyclic workflows without state corruption, and structured observability into every step.
Use it when:
Avoid skipping it if:
Best for: Simpler workflows with clear role separation
CrewAI reduces multi-agent setup to its simplest form: you define agents with roles and goals, assign them tasks, and the framework handles coordination.
It gives you maximum speed through opinionated structure.
For internal tooling, content automation pipelines, and MVPs where workflows are predictable and deadlines are real, CrewAI is hard to beat on time-to-working-system.
Its constraint is the flip side of that speed: fine-grained control over execution flow and custom routing logic requires workarounds that grow unwieldy over time.
Most teams treat CrewAI as a stepping stone but it gets you to a validated architecture faster, after which you graduate to more structured orchestration.
Use it when:
Avoid it when:
Best for: Complex multi-agent collaboration
AutoGen, maintained by Microsoft Research, is built around a core idea: agents should collaborate the way human teams do, iteratively, through conversation, with each agent contributing its specialisation to a shared task.
You define agents with roles and capabilities; AutoGen manages the conversation loop until the task is resolved.
This makes AutoGen genuinely powerful for tasks that benefit from iterative refinement, code generation with automated testing, research synthesis, multi-perspective analysis.
The same conversational flexibility that makes it powerful also makes it unpredictable.
Agent loops can run far longer than expected, token costs accumulate through conversation turns, and debugging a multi-agent conversation is significantly harder than debugging a deterministic graph.
Production note: Teams frequently pair AutoGen with LangGraph, using AutoGen for high-level task decomposition and collaboration, while LangGraph controls execution reliability for each agent's individual workflow. AutoGen as your sole production execution layer introduces significant unpredictability risk.
Use it when:
Avoid using it as:
Best for: Retrieval-heavy and knowledge-driven systems
LlamaIndex solves a problem that most framework comparisons underweight: getting the right data in front of the model at the right moment.
It handles ingestion, chunking, indexing, and query optimisation across structured and unstructured data sources, PDFs, databases, APIs, and vector stores.
In a RAG architecture, retrieval quality is the ceiling on output quality.
Use it when:
Avoid treating it as:
Best for: Enterprise-grade systems with governance needs
Semantic Kernel, developed by Microsoft, takes a structurally different approach from the other frameworks here.
It treats AI capabilities as composable, typed functions ("skills") that plug into existing enterprise software, Azure, Microsoft 365, Dynamics, and custom enterprise APIs.
Multi-language support (Python, C#, Java) makes it uniquely suited to large engineering organisations with heterogeneous stacks.
Its governance and auditability features are class-leading: full execution logging, role-based access control on skill invocations, and compliance-friendly deployment patterns.
The trade-off is exploration velocity, Semantic Kernel rewards disciplined, well-scoped integration projects and punishes free-form experimentation.
Use it when:
Avoid it when:
Each of these frameworks solves a piece of the problem.
The mistake is expecting one of them to do everything.
The systems that actually hold up are the ones where these pieces are put together the right way.
That is where architecture starts to matter more than individual tools.
The single most actionable insight from production work is this: the teams that build reliable agentic systems do not pick one framework.
They design a three-layer architecture where each layer uses the tool that is actually right for its job.
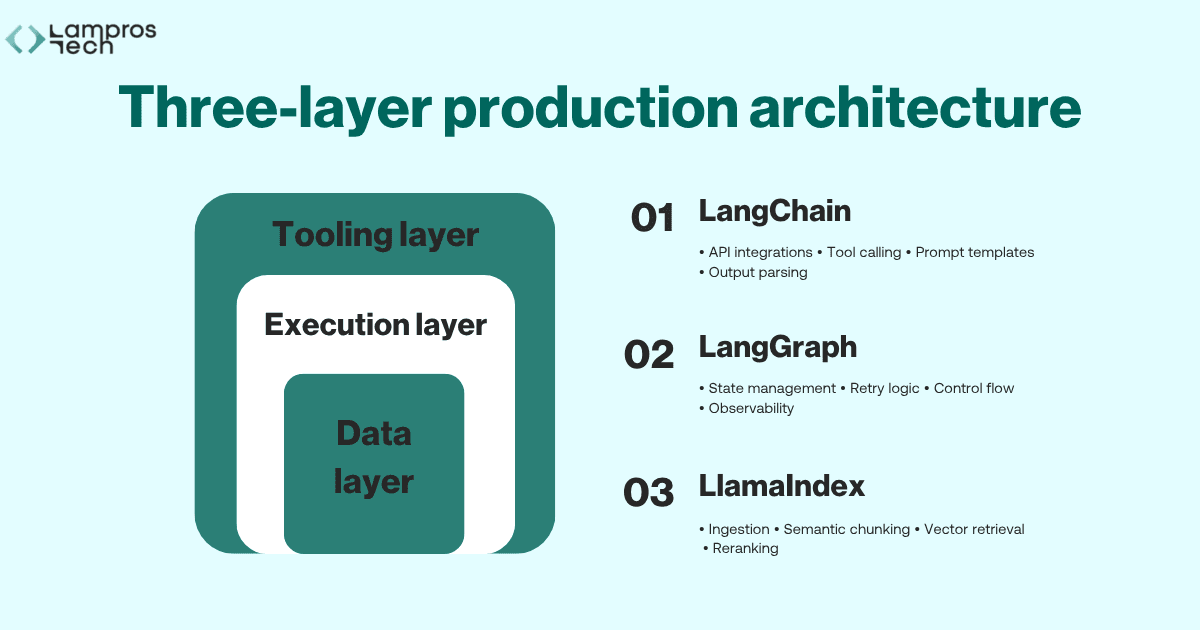
This three-layer AI agent architecture is the pattern we recommend to every engineering team building agentic systems in 2026:
This separation provides three compounding benefits.
Reliability improves because each layer has clear, bounded responsibilities. When something fails, you know exactly which layer to inspect.
Scalability improves because you can upgrade the retrieval layer (say, switching from FAISS to Weaviate) without touching your execution logic.
And debugging improves dramatically, because each layer is independently observable.
For systems requiring multi-agent collaboration, AutoGen sits above the execution layer as a coordination mechanism. It decomposes tasks and routes them to agents, each of which runs its own LangGraph workflow.
CrewAI can substitute in this position for simpler use cases.
In enterprise environments where governance requirements override flexibility, Semantic Kernel can replace the entire stack.
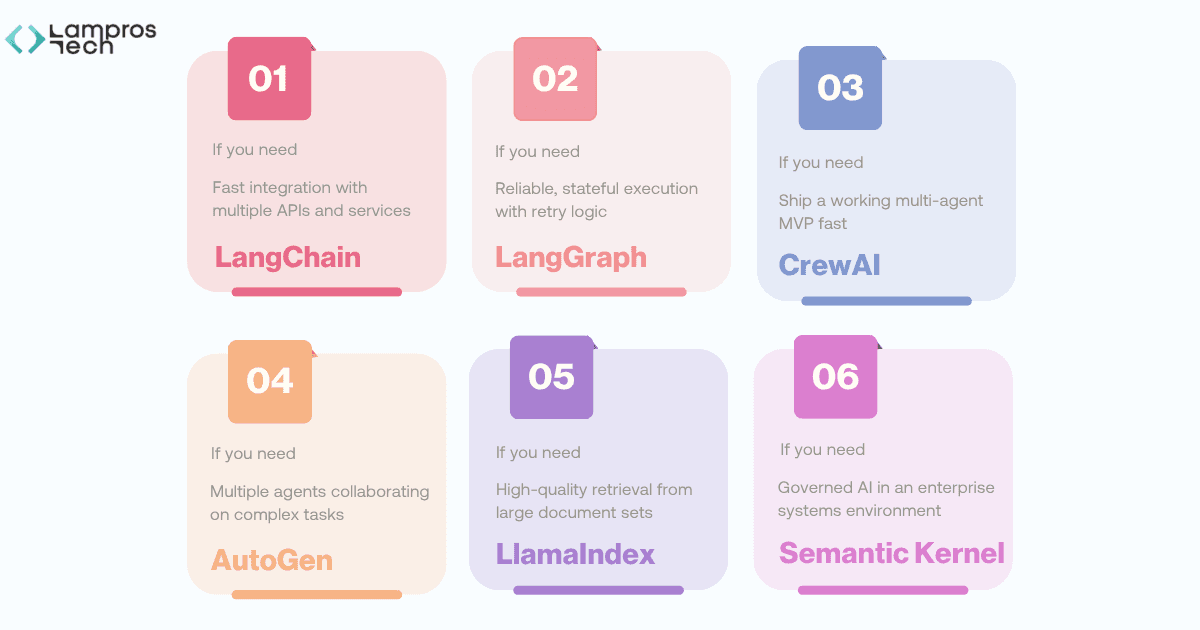
The choice is not permanent, and it is rarely singular.
The best production systems we have built treat framework selection as an ongoing architectural decision, something revisited when requirements change, not locked in at day one.
The shift to agentic systems is not incremental. It is foundational.
In 2026:
At Lampros Tech, we have seen that the biggest challenges do not come from model performance. They come from building systems that behave reliably under real-world conditions.
Choosing the right framework is not just a technical decision.It is an architectural one.
We work with engineering teams to design, build, and stabilise production-grade AI agent architectures, from initial framework selection through to LLMOps and observability.
If you're building an agentic system and want to get the architecture right from the start, schedule a call with our team.
We’ll walk through your current setup, identify where it might break in production, and help you design a more reliable path forward.

LangGraph is currently the strongest choice for production-grade agentic systems. Its graph-based execution model, explicit state management, and node-level retry policies directly address the most common failure modes in production AI agents.
LangChain is an integration and templating layer ideal for prototyping and RAG pipelines. LangGraph is a stateful execution framework built for production. They are complementary: many teams use LangChain for tool integrations and LangGraph for controlling the execution flow.
LLM orchestration refers to the layer of infrastructure that controls how an AI agent plans, executes, retries, and maintains state across multi-step workflows. It is the primary determinant of reliability in production agentic systems, more so than the underlying model.
AutoGen is powerful for iterative multi-agent collaboration but introduces unpredictability risk as a standalone production execution engine. Most engineering teams use it above a LangGraph execution layer rather than as a replacement for it.
Building an agentic system in production?
Move beyond experiments. Design AI systems with the right architecture, data, and workflows to deliver real business impact.
Let’s Talk

