


COO @ Quorivex Systems
We wanted to automate a few workflows but weren't sure where to start. Lampros helped us cut through the noise and get something useful into production quickly.

CTO @ Teralynx Systems
They picked up our processes surprisingly fast and built around how we already worked instead of forcing us into a new system.

Financial Technology Company
We saw value pretty quickly. A lot of repetitive work that used to take hours every week simply stopped being a problem. Our team could focus on higher-value work instead.
Contact Us
Ready to Ship AI Systems to
Let's align architecture, execution, and delivery from day one.
Published On Mar 31, 2026
Updated On Mar 31, 2026

AI adoption is accelerating rapidly, but building production-ready AI systems remains a major challenge.
The modern AI tech stack is no longer just about models.
It is a layered architecture that combines infrastructure, foundation models, retrieval systems, orchestration frameworks, and MLOps tooling to build scalable AI applications.
While prototypes can be built quickly, production systems require reliability, data integration, and controlled execution. This is where a structured AI stack becomes essential.
This guide breaks down the modern AI stack architecture, explains how each layer works, and outlines how teams build production AI systems in 2026.
A production AI system is structured across six layers:
Each layer plays a specific role in building scalable and reliable AI systems.
An AI stack is a layered architecture of infrastructure, models, data systems, orchestration, and monitoring tools used to build and run production AI applications.
It combines infrastructure, models, data systems, orchestration, and tooling into a structured architecture that enables AI systems to operate reliably in real-world environments.
Beyond this definition, AI systems are no longer built as isolated components.
Teams design them as layered systems, where each layer handles a specific responsibility, from computation and models to data, workflows, and monitoring.
This approach allows AI to move from experimentation into production.
In practice, the AI stack defines how models connect with data, integrate into applications, and maintain performance under real-world conditions.
AI development has shifted noticeably over the past few years.
Earlier, systems were largely model-centric.
Teams used to focus on training custom models, managing infrastructure manually, and stitching together pipelines with limited tooling.
Many of these systems remained experimental and difficult to scale.
That approach is now changing.
AI systems are increasingly being built as layered stacks rather than isolated models.
Engineering teams are now working across infrastructure, models, retrieval, orchestration, safety, and monitoring as part of a single system.
As per industry reports from McKinsey & Company and the Stanford AI Index show a clear shift toward API-based models, RAG architectures, and production-focused AI tooling.
As AI capabilities expand, the challenges teams encounter also evolve.
Building AI-powered applications increasingly involves handling performance, reliability, data integration, and safety alongside model capabilities.
In this context, the AI stack becomes less of a conceptual model and more of a practical necessity.
A layered approach provides a way to organise these concerns, helping teams structure systems in a way that is easier to develop, scale, and maintain over time.

From infrastructure to developer tooling, each layer plays a critical role in transforming AI from experimentation into real-world systems.
At the base of this stack sits the infrastructure layer, which determines how these systems are actually run.
The Infrastructure and Compute layer forms the foundation of the AI stack. Every AI system depends on this layer to train models, run inference, and serve responses to applications.
Unlike traditional software workloads, AI models require specialised hardware capable of handling massive parallel computations and large memory requirements.
To support this, engineering teams rely on a combination of cloud infrastructure, GPU hardware, and model-serving systems.
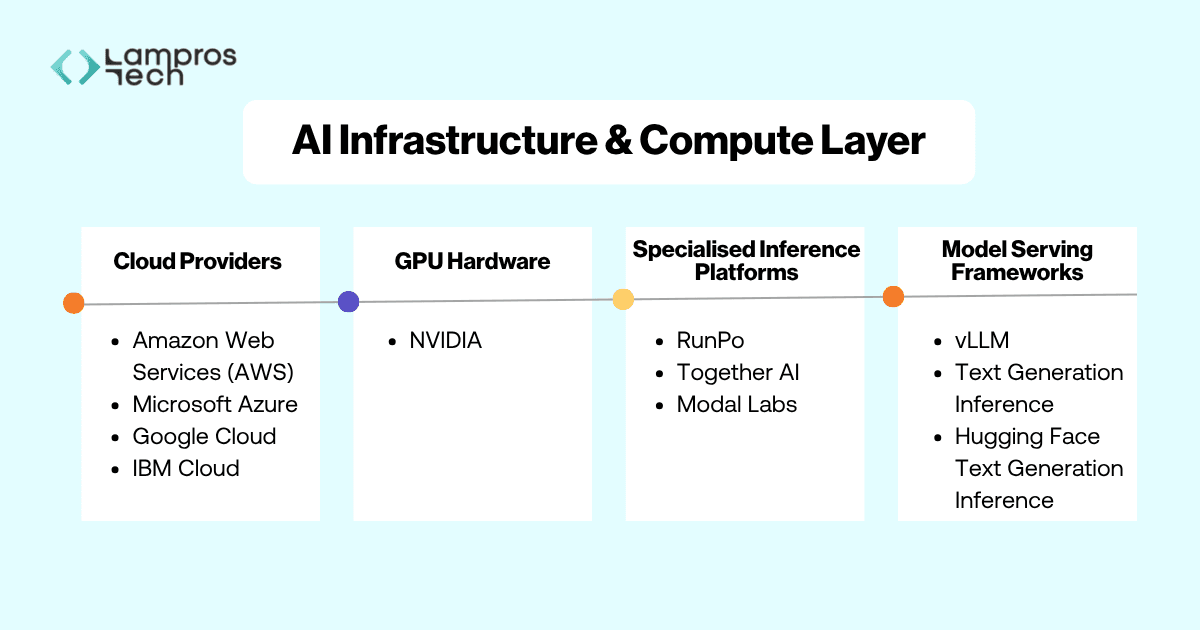
Cloud infrastructure has become the default foundation for running AI workloads, offering the scalability and flexibility required for both training and inference.
Most AI workloads run on cloud platforms such as:
These providers offer GPU enabled instances, distributed storage, and scalable infrastructure required to deploy AI applications.
When selecting a provider, teams often consider pricing, GPU availability, regional infrastructure, and integration with their existing development ecosystem.
The performance of modern AI systems is closely tied to GPU capabilities, making hardware selection a critical factor in both efficiency and cost.
The majority of modern AI workloads rely on GPUs produced by NVIDIA, whose hardware and CUDA software ecosystem power many training and inference environments across the industry.
Alongside hyperscalers, specialised inference platforms are increasingly used to optimise performance, reduce costs, and simplify deployment of AI models.
They often provide more efficient GPU utilisation and faster iteration cycles, particularly for teams working with high-volume inference workloads.
Platforms such as RunPod, Together AI, and Modal Labs are widely used to optimise inference performance and reduce infrastructure overhead.
As teams move toward self-hosted and open-weight models, model serving frameworks play a central role in managing inference and system efficiency.
When organisations run open models themselves, they often rely on frameworks like vLLM, Ollama, and Hugging Face Text Generation Inference to manage inference, optimise GPU utilisation, and expose APIs for applications.
This infrastructure layer ultimately determines how efficiently AI systems perform and scale in production.
Once that foundation is set, the focus naturally shifts to what these systems can actually do, which comes from the models themselves.
This layer represents where AI systems derive their core intelligence.
It plays a central role in modern generative AI development, powering applications such as copilots, assistants, and intelligent interfaces.
In practice, most engineering teams do not build these models themselves. Instead, they decide how to access and integrate them into their systems.
That decision often shapes the capabilities, constraints, and flexibility of the overall architecture.
The foundation model layer enables systems to understand natural language, generate responses, write and debug code, and reason across multi-step tasks.
Without this layer, the rest of the stack has no functional intelligence to operate on.
In practice, teams typically choose between two approaches to access these models: API-based models and open-weight models.
Each approach represents a different trade-off between speed, control, and operational complexity, and is often selected based on the stage of the product and specific system requirements.
API-based models - faster to build, less control
API-based models allow teams to quickly integrate intelligence without managing infrastructure, making them suitable for rapid development and early-stage systems.
Open-weight models - more control, higher complexity
Open-weight models, on the other hand, provide greater control over performance, cost, and data, but require additional engineering effort to deploy and maintain.
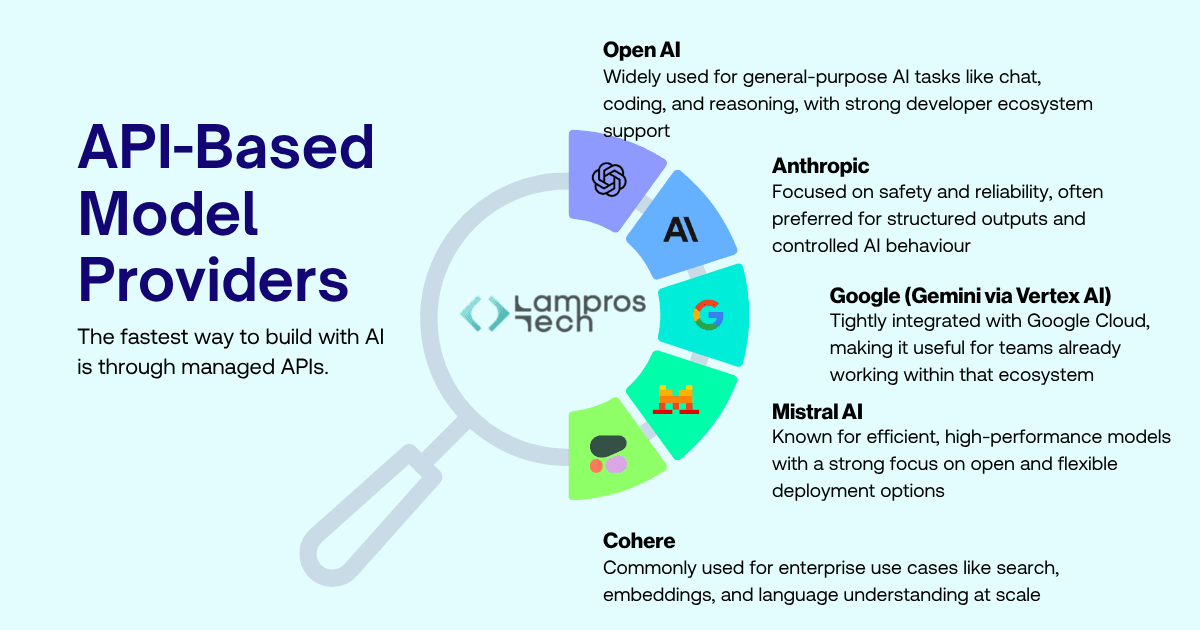
The fastest way to build with AI is through managed APIs.
Leading providers include:
With a single API call, developers can plug intelligence directly into their applications.
No infrastructure. No model training. No deployment complexity.
This is why most teams start here.
You can go from idea to working prototype in hours.
But that speed comes with trade-offs.
An alternative approach is using open-weight models such as those from Meta (LLaMA family of models).
Instead of relying on external APIs, teams can deploy these models on their own infrastructure. This
provides greater control over performance, data privacy, and cost optimization.
These models are widely used as the foundation for self-hosted and fine-tuned AI systems.
However, this flexibility introduces complexity. Teams must handle model serving, infrastructure management, scaling, and optimisation.
As a result, open-weight models are typically adopted by teams with stronger engineering capabilities or specific requirements around control and privacy.
Foundation models power a wide range of AI applications, including:
In production systems, these models are rarely used in isolation.
They are combined with retrieval systems, orchestration frameworks, and guardrails to deliver reliable and context-aware outputs.
Even the most capable models have a limitation. They do not have access to your real-time or proprietary data.
To make them useful in production systems, they need to be connected to external knowledge sources.
Retrieval-Augmented Generation (RAG) is a method that combines model outputs with real-time retrieved data to generate context-aware responses.
To make AI systems relevant, engineering teams need a way to connect models with external knowledge.
This is done through retrieval systems that fetch relevant data at runtime and pass it to the model before generating a response.
This approach allows AI systems to operate on current, proprietary, and context-specific information, rather than relying only on pretrained knowledge.
In practice, modern retrieval systems are built around two key components: vector databases and retrieval-augmented generation (RAG).
Together, these components form the foundation of most production retrieval systems.
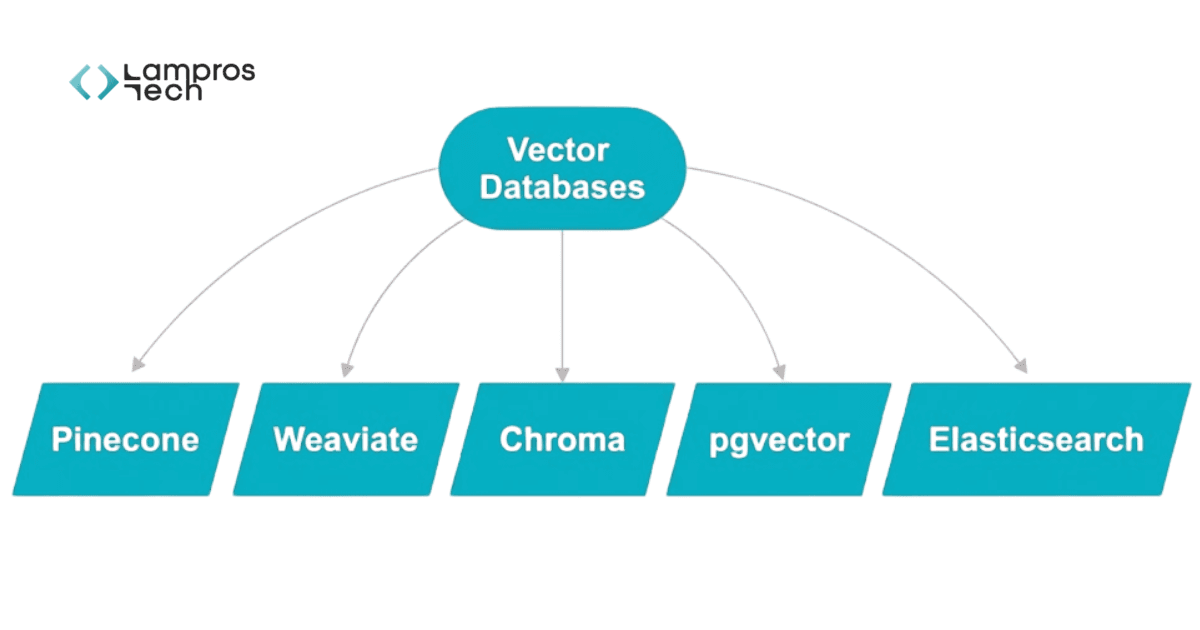
Vector databases handle how data is stored and retrieved. They convert data into embeddings and enable similarity-based search, allowing systems to find relevant information based on meaning rather than exact keywords.
Most modern retrieval systems are built on vector databases such as
These systems store data as embeddings and enable similarity search, allowing the system to retrieve information based on meaning rather than exact keywords.
Retrieval-Augmented Generation (RAG) is a method that improves AI accuracy by combining model outputs with real-time data retrieval.
RAG defines how this retrieved information is used. It combines relevant context with model inputs at runtime, enabling the system to generate responses that are grounded in real data.
And it is the most common pattern used in production.
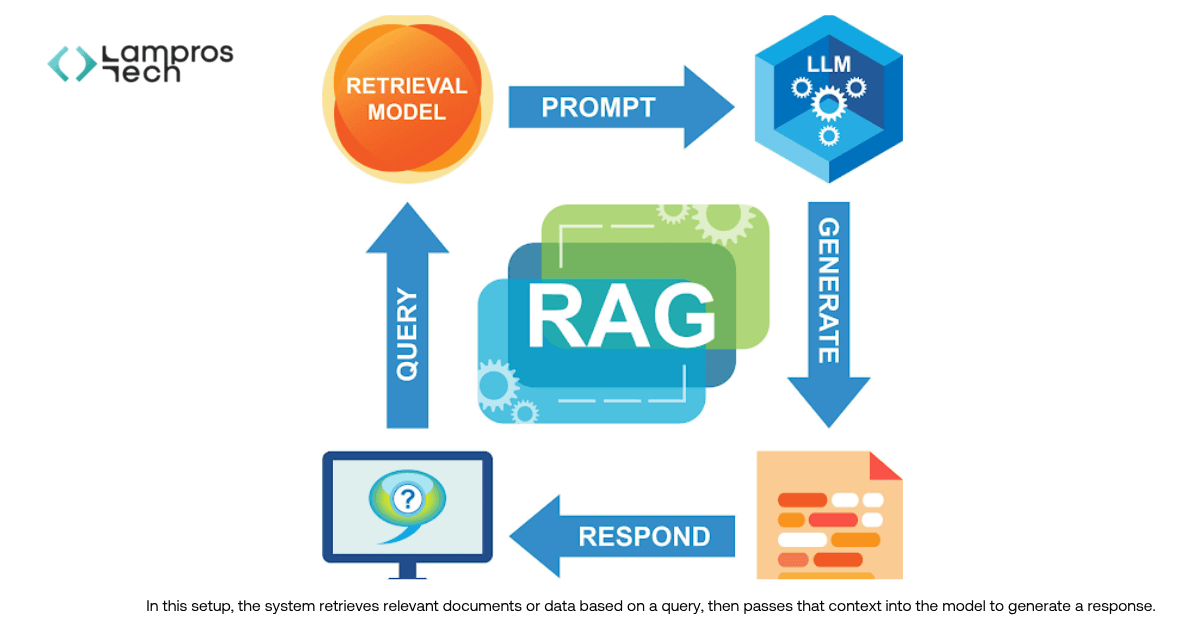
This improves accuracy, reduces hallucinations, and ensures outputs are grounded in real data.
Teams must design:
Small decisions here significantly affect output quality.
Once models are connected to data, the next challenge is coordination, how different components work together as a system.
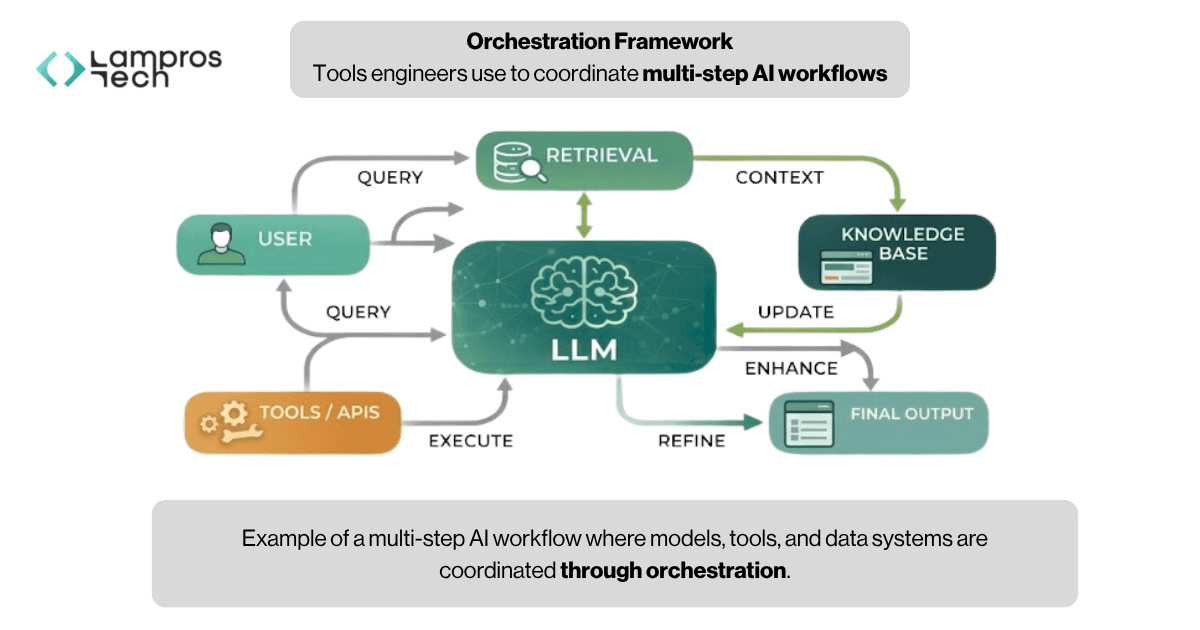
AI orchestration defines how models, data, and tools work together in a multi-step workflow.
In practice, AI systems are not single-step. A single user request often triggers multiple actions, retrieving data, constructing prompts, calling models, using external tools, and refining outputs.
Orchestration frameworks manage this flow, ensuring that each step happens in the right sequence and that the system behaves consistently.
Orchestration acts as the coordination layer of an AI system.
It connects models, data sources, and external tools into a structured workflow, allowing systems to:
The flow of a multi-step AI system can be visualised as follows:
To manage this complexity, engineering teams use frameworks such as:
These frameworks help structure how AI systems operate. They define the flow of execution, manage state across steps, and handle interactions between models, data sources, and external tools.
In practice, they allow teams to:
Agent frameworks take orchestration a step further by introducing dynamic decision-making.
Instead of following a fixed sequence, agents can decide what actions to take based on the task and context.
Common agent frameworks include:
These frameworks enable systems to:
This makes them useful for complex or open-ended workflows, though they can be harder to control and debug compared to structured pipelines.
At this layer, teams typically choose between two approaches:
• Structured pipelines - predictable, easier to debug, production-friendly
• Agent-based systems - flexible and adaptive, but harder to control
Most production systems rely on structured workflows, introducing agents selectively where flexibility is needed.
As these systems become more capable and autonomous, ensuring safe and reliable behaviour becomes increasingly important.
In production AI systems, guardrails are not optional. They are required to ensure reliability, safety, and compliance.
As AI systems move into real-world use, reliability becomes just as important as capability.
Even well-designed systems can produce incorrect, unsafe, or misleading outputs. While this may be acceptable during experimentation, it creates real risks in production environments.
This is where guardrails come in.
Guardrails act as a control layer around AI systems.
They help monitor and shape how models behave by:
As AI systems interact with users, certain risks become common:
These are not edge cases. They are expected challenges in production systems.
Without safeguards, these issues directly affect user trust and system reliability.
Engineering teams use tools such as:
These tools provide structured ways to enforce rules and validate model behaviour before responses reach the user.
Guardrails introduce control into otherwise probabilistic systems.
They help teams:
With safety in place, the next focus is visibility and improvement over time.
MLOps is what separates experimental AI systems from production-ready systems.
Building AI systems is only part of the process. Maintaining and improving them is equally important.
As systems move into production, teams need visibility into how models perform, where they fail, and how they evolve over time.
This is where developer tooling and MLOps come in.
This layer provides the feedback loop needed to build, monitor, and improve AI systems.
It helps teams:
AI is also used to accelerate development itself.
Tools such as:
Help accelerate development by assisting with code generation, debugging, and implementation.
AI systems can be difficult to debug without visibility into what is happening internally.
Tools such as:
Allow teams to track model calls, inspect prompts, and monitor system behaviour in production.
Improving AI systems requires continuous evaluation.
Tools such as:
Help measure model performance, compare experiments, and detect regressions over time.
AI systems are not static.
They evolve with new data, models, and use cases. Without proper tooling, systems become difficult to understand and improve.
This layer enables teams to iterate, optimise, and maintain reliability as their systems scale.
With all layers in place, the real question becomes how these components come together in actual production systems.
Understanding the AI stack is one part of the process. Applying it effectively across real systems is where most of the work happens.
In practice, building production AI requires coordinating multiple layers together, from models and data to workflows, safety, and monitoring.
At Lampros Tech, we work across these layers to help teams move from prototypes to production:
This layered approach helps ensure that AI systems are not just functional, but scalable, reliable, and aligned with real product requirements.
Stepping back, the full picture of the AI stack begins to come together.
Most teams follow a phased approach:
Modern AI systems are no longer model-centric. They are layered systems where each component plays a defined role in delivering reliable, production-ready performance.
Each layer addresses a specific challenge, from infrastructure and models to data, orchestration, safety, and monitoring.
Most teams start simple, often with a single model API. As systems grow, they introduce retrieval, orchestration, and guardrails to handle real-world complexity.
Understanding the AI stack helps teams design these systems intentionally, rather than reacting to issues as they arise.
At Lampros Tech, we help teams move from prototype to production by designing and building full-stack AI systems across infrastructure, RAG, agents, and MLOps.
If you're building beyond demos, let’s talk.

The modern AI stack is a layered system of technologies used to build, deploy, and scale AI applications. It includes infrastructure, models, data retrieval, orchestration, and monitoring.
RAG (Retrieval-Augmented Generation) improves AI outputs by combining model responses with real-time or external data, making responses more accurate and context-aware.
AI orchestration manages how models, data, and tools interact in a structured workflow, ensuring multi-step AI processes run reliably.
Foundation models are large AI models that power tasks like text generation, reasoning, and coding. They act as the core intelligence layer in modern AI systems.
Guardrails help ensure AI systems produce safe and reliable outputs by validating responses, enforcing rules, and reducing risks like hallucinations or unsafe content.
Build AI Systems That Actually Work in Production
Move beyond experiments. Design AI systems with the right architecture, data, and workflows to deliver real business impact.
Let’s Talk


