


COO @ Quorivex Systems
We wanted to automate a few workflows but weren't sure where to start. Lampros helped us cut through the noise and get something useful into production quickly.

CTO @ Teralynx Systems
They picked up our processes surprisingly fast and built around how we already worked instead of forcing us into a new system.

Financial Technology Company
We saw value pretty quickly. A lot of repetitive work that used to take hours every week simply stopped being a problem. Our team could focus on higher-value work instead.
Contact Us
Ready to Ship AI Systems to
Let's align architecture, execution, and delivery from day one.
Published On Nov 26, 2025
Updated On Nov 26, 2025

The Ethereum ecosystem grant landscape has hardened.
Less than 1 in 8 proposals now pass early review across Arbitrum, Optimism Missions, Base Builder Seasons, and Scroll zkEVM programs.
If you’re building in the Ethereum ecosystem, those are your odds.
Reviewers fund teams that show traction, ecosystem fit, and measurable progress, and move forward.
Securing a grant in this phase demands clarity, data, and precision. Yet most teams still miss the signals that matter most.
This guide breaks down why that happens and how to fix the mistakes before your next submission.
Let’s begin one by one.
Ethereum grant programs in 2025 are selective by design.
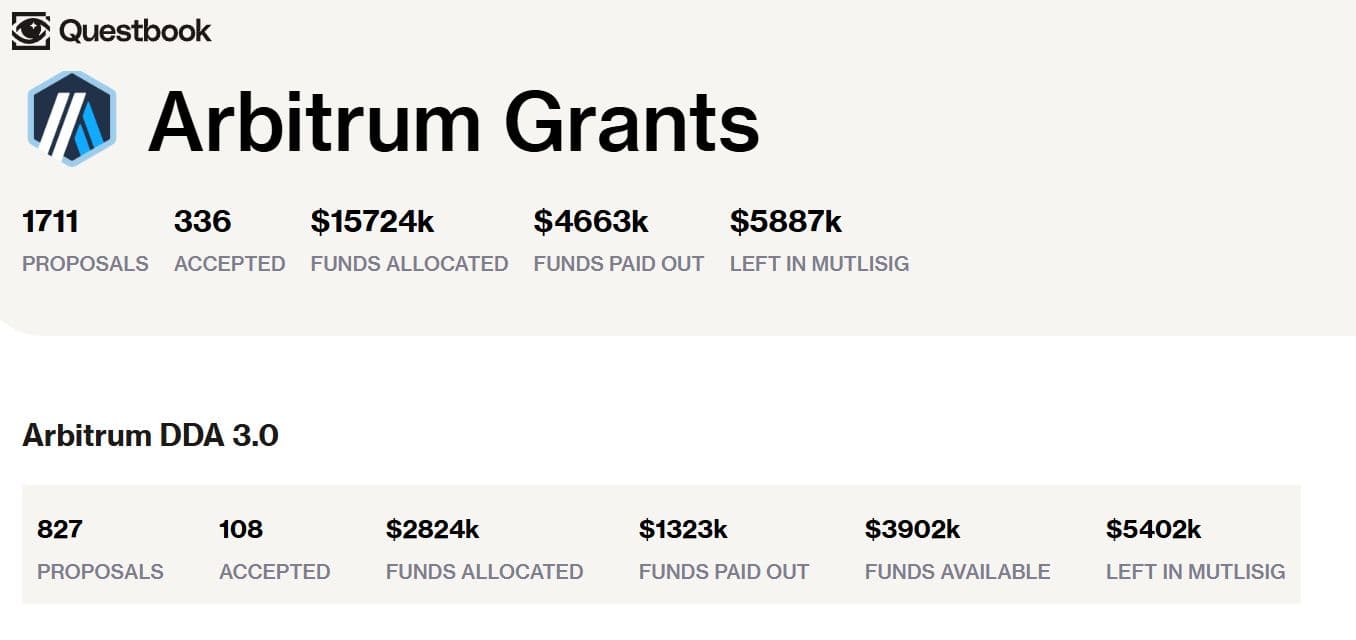
As the Questbook Arbitrum dashboard (Nov 2025) shows, only 108 of 827 proposals under Arbitrum DDA 3.0 were approved, and the acceptance rate is nearly 13%.
This sharp filter reflects a shift that ecosystems now reward alignment over abstraction.
Proposals that directly solve live bottlenecks within a defined domain, such as Stylus tooling, Orbit observability, or OP Stack consistency, are prioritised.
Those framed as broadly useful for Web3 rarely make it past the first review.
Each ecosystem operates within its own strategic bottlenecks, which can be technical, governance, or adoption-related.
When assessing a proposal, reviewers begin with one question:
“Does this proposal directly accelerate a bottleneck within one of our active domains?”
That single filter determines initial scoring. Ecosystem teams look for alignment, not just abstraction.
Their priorities are sharp and constantly shifting:
These are not just assumptions, they’re documented priorities across Arbitrum’s DDA 3.0, Optimism Mission Requests, and Base Builder Grants.
For instance, Arbitrum’s DAO strategic update sets KPIs around Orbit chain launches and a critical tooling gap in safety and monitoring.
Similarly, Optimism’s Q3 2025 Mission Requests highlight inter-rollup communication reliability as a funded bottleneck.
Even strong technical teams misstep here. The most common reasons:
Reviewers recognize these gaps instantly. A technically good proposal still fails if its domain alignment is unclear.
Anchor your proposal to a verified ecosystem signal, not just with an assumption. Take reference from official updates, governance posts, or dashboards.
For example, Arbitrum DDA 3.0 reviews have repeatedly flagged the lack of standardized safety and monitoring tools for Orbit appchains.
If your proposal directly targets that, make the connection explicit.
Reflect the stack you’re building for. Reviewers notice technical vocabulary like Stylus modules, OP Stack clients, Scroll prover circuits, or Base SDK workflows.
Precision in phrasing signals depth in understanding.
Your roadmap should parallel the chain’s own evolution.
This shows reviewers that your progress compounds the ecosystem’s strategic trajectory.
Strong proposals don’t just describe what they will do instead, they show what happens if the bottleneck isn’t solved.
Example: Without trust-minimised bridging, Orbit appchains face rising fragmentation and capital inefficiency.
This urgency framing is a differentiator in 2025 reviews.
Evidence matters more than promise. Teams need to include testnet deployments, code commits, or early ecosystem collaborations.
Grant reviewers increasingly prioritize proof of execution over project intent.
But domain alignment isn’t enough, because reviewers still need proof that the problem you’re solving is real, recurring, and ecosystem-validated.
In 2025, ecosystem grants across Ethereum’s L2 landscape reward validated pain, not speculative opportunity.
A proposal may be technically solid, but if it doesn’t address a bottleneck the ecosystem itself has surfaced, it rarely moves past initial review.
Reviewers inside any ecosystem, be it Arbitrum, Optimism Missions, Base Seasons, and Scroll zkEVM cycles, ask one question:
“Has the ecosystem acknowledged this problem, and can you prove it exists?”
Reviewers look for patterns like:
If those signals are missing, the “problem” is treated as noise.
Start by anchoring your proposal in signals the ecosystem itself has surfaced, governance threads, foundation updates, developer RFCs, or on-chain telemetry.
Every ecosystem, whether built on the OP Stack, Orbit SDK, Polygon CDK, or a custom zkEVM, has public indicators of where friction exists.
Examples of credible signals:
Teams can use each ecosystem’s public documentation, engineering updates, or governance metrics to extract a real, surfaced pain point.
Once identified, support the problem with measurable, on-chain, or infra evidence. Reviewers trust quantification over narrative.
Examples of how to make it tangible:
Numbers build trust. A small chart from your test logs often tells the story better than a paragraph of claims.
Ecosystem grants are not written to reward innovation in isolation, but they’re designed to de-risk the network’s trajectory.
Frame your proposal in terms of what fails if this bottleneck persists:
Show reviewers what the downside looks like. Ecosystems react faster to risk than to features.
One comment or forum post isn’t enough proof. Reviewers look for patterns, not opinions.
To make your problem statement credible, back it up from different, reliable places:
When these signals align, reviewers see it as a real, recurring ecosystem pain, not just your personal assumption.
Even after defining the problem clearly, another critical filter remains: demonstrating enough traction to prove your team can actually execute.
That’s the next mistake.
In 2025, the difference between a funded and a rejected grant submission in the Ethereum ecosystem often isn’t the idea, but it’s the proof that you’ve begun building.
Reviewers are no longer willing to imagine your progress; they expect to see it.
When assessing proposals for ecosystems such as Arbitrum Foundation (DDA 3.0), Optimism Foundation (Superchain Missions), Base Labs (Builder Seasons) and Scroll Labs (zkEVM Grants), reviewers ask:
“Do we have evidence this team can deliver?”
They look for:
If your submission lacks all of this, reviewers default to treating it as conceptual, not operational.
Your MVP doesn’t need to be market-ready, it needs to be verifiable. Launch something small, public, and functioning.
For example:
In 2025, teams with visible builds had significantly higher success rates in grant screening.
Your code repository is your execution track record. Reviewers look for:
A repository with 6+ months of consistent activity is a strong signal of reliability.
A concise one-pager that describes:
For example, In an Orbit-based devnet, we observed that state-size expansion led to higher RAM and read latency, so we applied compression logic and reduced latency materially (e.g., a drop in p95 latency).
This gives reviewers concrete data, not just speculation.
Referring to builder calls, delegate feedback, or integration trials demonstrates you’re not working in isolation.
Phrase it like:
“We engaged two builder teams on Orbit devnet, ran our monitoring hook, and refined based on their latency logs.”
Mentioning that interaction signals you’re aligned with the ecosystem’s stack priorities.
Complete meaningful milestones before submitting. Even basic completions count:
This evidence points shift in the proposal from “planned” to “already in motion”. Reviewers consider this lower risk and higher priority for funding.
For reviewers, traction isn’t optional. It is the strongest currency in modern grant evaluation.
And even with traction, teams lose credibility fast if they misjudge the next filter: unrealistic milestones, timelines, and budgets.
That’s Mistake 4.
The fastest way to lose reviewer confidence is to overpromise and under-specify.
Ambitious plans may sound inspiring to founders, but to reviewers, compressed timelines, inflated KPIs, or unrealistic budgets signal something else: inexperience in real L2 execution.
Modern Ethereum-aligned ecosystems operate under production-grade constraints like gas dynamics, audit queues, version drift, and prover latency.
If your plan doesn’t reflect that reality, it won’t survive technical due diligence.
Every serious grant committee, whether under Arbitrum’s DDA 3.0, Optimism’s Superchain Missions, Base Builder Seasons, or zkEVM grant rounds, begins with one filter:
“Can this team deliver this plan under real-world network conditions?”
They examine:
Phrases like “Phase 2: Infrastructure build-out” or “Enhance scalability” mean nothing to reviewers. They expect testable outputs:
Timelines that skip audits, version upgrades, or testnets show poor planning discipline.
A credible timeline accounts for design → implementation → unit & integration tests → testnet deployment → partner feedback → audit → mainnet readiness, with buffers for version drift or infra delays.
Budgets that are too low or too high both break trust. In 2025, reviewer references are roughly:
If your numbers fall outside these ranges without justification, reviewers assume you haven’t priced execution realistically.
KPIs that promise “10x throughput” or “universal onboarding” without measurable targets read as marketing, not metrics. Impact must tie directly to observable chain primitives:
These failure signals are frequently called out in grant reviews and forum commentary when reviewers explain rejections.
Avoid “phases” and focus on what can be measured or deployed. Instead of “Build core infra,” say:
“Deploy batcher API v1 on devnet, execute 50 cross-rollup test transactions, publish results to repository.”
Reviewers fund concrete outputs, not abstract progress.
Show the real sequence: design → build → test → integrate → audit → deploy.
Include 15-25 % time buffer for audits, version misalignment, or L2 infra updates. This shows operational maturity.
Divide budgets into modules:
Use public data from Questbook domain allocations, past LTIPP reports, or Foundation transparency dashboards as reference points.
Tie each KPI to something reviewers can independently verify:
This level of specificity builds credibility.
Every stack evolves. Reviewers expect awareness of moving parts.
List external dependencies (e.g., OP Stack upgrades, Sequencer API changes, prover releases) and mitigation steps (e.g., fallback RPCs, version locks, modular adapters).
A simple risks & mitigations table demonstrates foresight.
Use previously funded proposals as calibration references.
If your structure and numbers mirror past successful Questbook or LTIPP projects, reviewers interpret your plan as familiar, executable, and trustworthy.
Before reviewers ever read your words, they measure your plan’s realism. But once they do, the next filter is tone, and that’s where many teams fail.
AI is useful. It helps structure sections, tighten grammar, and keep formatting clean. The problem is not the tool.
The problem is content that reads like it was generated by someone who did not build the thing.
Reviewers across Arbitrum, Optimism, Base, Scroll, zkSync, Linea, and Starknet see the same patterns every cycle.
They do not penalize AI; they penalize the absence of chain-specific insight and missing technical fingerprints.
Reviewers don’t judge writing quality. They judge whether the writing reflects:
If these are missing, it does not matter how smooth the prose is. It reads like marketing. Reviewers move on.
Let AI help format sections or clean grammar. But every claim, nuance, and technical detail must come from the team’s real work.
For example:
One verifiable artifact is worth more than ten smooth paragraphs.
Prefer concrete nouns and verbs: “batcher API”, “inbox proof”, “sequencer retries”, “prover queue”, “session init”.
Even one line like: “During early testing, our Scroll prover integration stalled on batch 64 until we adjusted the circuit parameters.”
This level of detail is impossible for AI to fake convincingly.
AI is not disqualifying. Lack of substance is. The proposals that win read like a lab notebook from the actual team: parameter choices, versions, errors, fixes, and measurable outcomes tied to the target chain.
A proposal that could only have been written by your team is the one reviewers support.
You now understand the five mistakes that quietly eliminate strong teams long before reviewers reach the final vote.
These aren’t theoretical pitfalls; they’re patterns that repeat across Arbitrum, Optimism Missions, Base Seasons, Scroll zkEVM cycles, and every ecosystem that has matured past early-stage funding.
The shift is simple: Ecosystem grants in 2025 don’t fund ideas. They fund evidence.
Reviewers want to see:
When these elements come together, a grant becomes an accelerant instead of a dependency. When they’re missing, even the strongest concept collapses in screening.
And that’s the transition point teams need to internalize: A high-quality proposal isn’t about writing more. It’s about showing more context, more proof, more ownership, more clarity.
At Lampros Tech, we help builders turn execution into evidence and evidence into funding.
Our grant support program framework aligns your proposal with what reviewers actually prioritize: clarity, traction, and credibility.

Most proposals fail because they don’t align with an ecosystem’s active priorities or domain bottlenecks. Programs like Arbitrum DDA 3.0 and Optimism Missions now fund solutions tied to measurable network needs, not broad Web3 ideas. Lack of traction, unclear milestones, or unrealistic budgets are common rejection triggers.
Successful teams map their proposal to real bottlenecks—such as Orbit observability, OP Stack reliability, or Base account abstraction. They show proof of execution through testnets, GitHub commits, and measurable KPIs. Reviewers fund evidence, not intent.
Reviewers look for ecosystem fit, clarity, and proof of delivery. They evaluate traction, domain alignment, technical realism, and measurable impact. A proposal that mirrors the ecosystem’s roadmap (like Arbitrum’s Orbit tooling or Optimism’s cross-rollup stability) scores higher.
An effective grant proposal includes:
Measurable KPIs tied to network performance Proposals that show progress before funding often outperform those starting from zero.
Lampros Tech helps teams turn execution into evidence. Our Grant Support Framework aligns proposals with what reviewers prioritize: domain fit, measurable progress, and transparency. We help structure milestones, define KPIs, and build credibility across ecosystems like Arbitrum, Optimism, Base, and Scroll.
Grant Support
End-to-end support across discovery, proposals, milestones, and transparent reporting.
Let’s Talk

